
Photo by Justin Morgan on Unsplash
KMeans Clustering for Mall Customers Dataset
Spark ML + PCA (Principal Component Analysis)


Table of contents
- The Dataset
- Market Analysis
- Load libraries
- Launch Spark session
- Import dataset
- Print Schema
- Remove unwanted columns
- Encode Gender with pipeline
- Check the DF
- Check and delete NAN / Null values
- Build our model
- VectorAssembler
- Standarize the data
- Compute summary statistics by fitting the StandardScaler
- Normalize each feature to have unit standard deviation and mean
- Launch Model
- Feature density
- PCA
- Plot our clusters
The Dataset
Market Analysis
We have a supermarket mall and through membership cards , we have got some basic data about our customers like Customer ID, age, gender, annual income and spending score. Spending Score is something we have assigned to the customer based on defined parameters like customer behavior and purchasing data.
!pip3 install pyspark
Collecting pyspark
Downloading pyspark-3.2.1.tar.gz (281.4 MB)
|████████████████████████████████| 281.4 MB 37 kB/s
Collecting py4j==0.10.9.3
Downloading py4j-0.10.9.3-py2.py3-none-any.whl (198 kB)
|████████████████████████████████| 198 kB 50.4 MB/s
Building wheels for collected packages: pyspark
Building wheel for pyspark (setup.py) ... done
Created wheel for pyspark: filename=pyspark-3.2.1-py2.py3-none-any.whl size=281853642 sha256=4c678bb0f6f2dc14b5013eb3706bd1a15aaa79422624f570ef78d9c04fb6884f
Stored in directory: /root/.cache/pip/wheels/9f/f5/07/7cd8017084dce4e93e84e92efd1e1d5334db05f2e83bcef74f
Successfully built pyspark
Installing collected packages: py4j, pyspark
Successfully installed py4j-0.10.9.3 pyspark-3.2.1
Load libraries
import pandas as pd
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkContext
from pyspark.conf import SparkConf
Launch Spark session
conf = SparkConf().set('spark.ui.port', '4050')
sc = SparkContext(conf=conf)
spark = SparkSession \
.builder \
.appName('Basics') \
.getOrCreate()
Import dataset
df = spark.read.csv(path='Mall_Customers.csv', header=True, inferSchema=True)
df.take(10)
[Row(CustomerID=1, Gender='Male', Age=19, Annual Income (k$)=15, Spending Score (1-100)=39),
Row(CustomerID=2, Gender='Male', Age=21, Annual Income (k$)=15, Spending Score (1-100)=81),
Row(CustomerID=3, Gender='Female', Age=20, Annual Income (k$)=16, Spending Score (1-100)=6),
Row(CustomerID=4, Gender='Female', Age=23, Annual Income (k$)=16, Spending Score (1-100)=77),
Row(CustomerID=5, Gender='Female', Age=31, Annual Income (k$)=17, Spending Score (1-100)=40),
Row(CustomerID=6, Gender='Female', Age=22, Annual Income (k$)=17, Spending Score (1-100)=76),
Row(CustomerID=7, Gender='Female', Age=35, Annual Income (k$)=18, Spending Score (1-100)=6),
Row(CustomerID=8, Gender='Female', Age=23, Annual Income (k$)=18, Spending Score (1-100)=94),
Row(CustomerID=9, Gender='Male', Age=64, Annual Income (k$)=19, Spending Score (1-100)=3),
Row(CustomerID=10, Gender='Female', Age=30, Annual Income (k$)=19, Spending Score (1-100)=72)]
Print Schema
df.printSchema()
root
|-- CustomerID: integer (nullable = true)
|-- Gender: string (nullable = true)
|-- Age: integer (nullable = true)
|-- Annual Income (k$): integer (nullable = true)
|-- Spending Score (1-100): integer (nullable = true)
Remove unwanted columns
cols = ['CustomerID']
for col in cols:
df = df.drop(col)
df.printSchema()
root
|-- Gender: string (nullable = true)
|-- Age: integer (nullable = true)
|-- Annual Income (k$): integer (nullable = true)
|-- Spending Score (1-100): integer (nullable = true
Encode Gender with pipeline
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer
indexer = StringIndexer(
inputCol= 'Gender',
outputCol= 'Gender_code'
)
pipeline = Pipeline(
stages =[indexer]
)
df_r = pipeline.fit(df).transform(df)
Count individuals by gender
a = df_r.groupBy('Gender_code').count().sort('Gender_code').show()
a
+-----------+-----+
|Gender_code|count|
+-----------+-----+
| 0.0| 112|
| 1.0| 88|
+-----------+-----+
Check the DF
df_r.show()
+------+---+------------------+----------------------+-----------+
|Gender|Age|Annual Income (k$)|Spending Score (1-100)|Gender_code|
+------+---+------------------+----------------------+-----------+
| Male| 19| 15| 39| 1.0|
| Male| 21| 15| 81| 1.0|
|Female| 20| 16| 6| 0.0|
|Female| 23| 16| 77| 0.0|
|Female| 31| 17| 40| 0.0|
|Female| 22| 17| 76| 0.0|
|Female| 35| 18| 6| 0.0|
|Female| 23| 18| 94| 0.0|
| Male| 64| 19| 3| 1.0|
|Female| 30| 19| 72| 0.0|
| Male| 67| 19| 14| 1.0|
|Female| 35| 19| 99| 0.0|
|Female| 58| 20| 15| 0.0|
|Female| 24| 20| 77| 0.0|
| Male| 37| 20| 13| 1.0|
| Male| 22| 20| 79| 1.0|
|Female| 35| 21| 35| 0.0|
| Male| 20| 21| 66| 1.0|
| Male| 52| 23| 29| 1.0|
|Female| 35| 23| 98| 0.0|
+------+---+------------------+----------------------+-----------+
only showing top 20 rows
Check and delete NAN / Null values
from pyspark.sql.functions import isnan, when, count, col, isnull
df = df_r
df.select([count(when(isnan(c), c)).alias(c) for c in df.columns]).show()
+------+---+------------------+----------------------+-----------+
|Gender|Age|Annual Income (k$)|Spending Score (1-100)|Gender_code|
+------+---+------------------+----------------------+-----------+
| 0| 0| 0| 0| 0|
+------+---+------------------+----------------------+-----------+
df.select([count(when(isnull(c), c)).alias(c) for c in df.columns]).show()
+------+---+------------------+----------------------+-----------+
|Gender|Age|Annual Income (k$)|Spending Score (1-100)|Gender_code|
+------+---+------------------+----------------------+-----------+
| 0| 0| 0| 0| 0|
+------+---+------------------+----------------------+-----------+
Build our model
cols = ['Annual Income (k$)','Spending Score (1-100)', 'Age']
df.select(cols).describe().show()
+-------+------------------+----------------------+-----------------+
|summary|Annual Income (k$)|Spending Score (1-100)| Age|
+-------+------------------+----------------------+-----------------+
| count| 200| 200| 200|
| mean| 60.56| 50.2| 38.85|
| stddev| 26.26472116527124| 25.823521668370173|13.96900733155888|
| min| 15| 1| 18|
| max| 137| 99| 70|
+-------+------------------+----------------------+-----------------+
VectorAssembler
from pyspark.ml.linalg import Vectors
from pyspark.ml.feature import VectorAssembler
cols.append('Gender_code')
vecAssembler = VectorAssembler(
inputCols= cols,
outputCol="features"
)
v = vecAssembler.transform(df)
v.show()
+------+---+------------------+----------------------+-----------+--------------------+
|Gender|Age|Annual Income (k$)|Spending Score (1-100)|Gender_code| features|
+------+---+------------------+----------------------+-----------+--------------------+
| Male| 19| 15| 39| 1.0|[15.0,39.0,19.0,1.0]|
| Male| 21| 15| 81| 1.0|[15.0,81.0,21.0,1.0]|
|Female| 20| 16| 6| 0.0| [16.0,6.0,20.0,0.0]|
|Female| 23| 16| 77| 0.0|[16.0,77.0,23.0,0.0]|
|Female| 31| 17| 40| 0.0|[17.0,40.0,31.0,0.0]|
|Female| 22| 17| 76| 0.0|[17.0,76.0,22.0,0.0]|
|Female| 35| 18| 6| 0.0| [18.0,6.0,35.0,0.0]|
|Female| 23| 18| 94| 0.0|[18.0,94.0,23.0,0.0]|
| Male| 64| 19| 3| 1.0| [19.0,3.0,64.0,1.0]|
|Female| 30| 19| 72| 0.0|[19.0,72.0,30.0,0.0]|
| Male| 67| 19| 14| 1.0|[19.0,14.0,67.0,1.0]|
|Female| 35| 19| 99| 0.0|[19.0,99.0,35.0,0.0]|
|Female| 58| 20| 15| 0.0|[20.0,15.0,58.0,0.0]|
|Female| 24| 20| 77| 0.0|[20.0,77.0,24.0,0.0]|
| Male| 37| 20| 13| 1.0|[20.0,13.0,37.0,1.0]|
| Male| 22| 20| 79| 1.0|[20.0,79.0,22.0,1.0]|
|Female| 35| 21| 35| 0.0|[21.0,35.0,35.0,0.0]|
| Male| 20| 21| 66| 1.0|[21.0,66.0,20.0,1.0]|
| Male| 52| 23| 29| 1.0|[23.0,29.0,52.0,1.0]|
|Female| 35| 23| 98| 0.0|[23.0,98.0,35.0,0.0]|
+------+---+------------------+----------------------+-----------+--------------------+
only showing top 20 rows
Standarize the data
from pyspark.ml.feature import StandardScaler
inputcols2 = cols
scaler = StandardScaler(inputCol='features', outputCol="scaledFeatures",
withStd=True, withMean=True)
Compute summary statistics by fitting the StandardScaler
scalerModel = scaler.fit(v)
Normalize each feature to have unit standard deviation and mean
scaledData = scalerModel.transform(v)
pd = scaledData.select('scaledFeatures').toPandas()
pd
scaledFeatures
0 [-1.7346462470822699, -0.43371311410706104, -1...
1 [-1.7346462470822699, 1.1927110637944185, -1.2...
2 [-1.696572361062027, -1.7116178253153662, -1.3...
3 [-1.696572361062027, 1.0378135230418966, -1.13...
4 [-1.658498475041784, -0.39498872891893055, -0....
... ...
195 [2.263111785043241, 1.1152622934181575, -0.275...
196 [2.491555101164699, -0.8596813511764961, 0.440...
197 [2.491555101164699, 0.9216403674775052, -0.490...
198 [2.9103678473873713, -1.2469252030578006, -0.4...
199 [2.9103678473873713, 1.2701598341706792, -0.63...
200 rows × 1 columns
Launch Model
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
kmeans = KMeans().setK(5)
model = kmeans.fit(scaledData)
predictions = model.transform(scaledData)
evaluator = ClusteringEvaluator()
silhouette = evaluator.evaluate(predictions)
print("Silhouette with squared euclidean distance = " + str(silhouette))
# Shows the result.
centers = model.clusterCenters()
print("Cluster Centers: ")
for center in centers:
print(center)
pred = model.summary.predictions
pred.show()
Silhouette with squared euclidean distance = 0.6283560223340561
Cluster Centers:
[55.48051948 49.32467532 43.72727273 0.4025974 0.4025974 ]
[28.04 77. 24.96 0.44 0.44]
[87.75 17.58333333 40.66666667 0.52777778 0.52777778]
[86.53846154 82.12820513 32.69230769 0.46153846 0.46153846]
[26.30434783 20.91304348 45.2173913 0.39130435 0.39130435]
+------+---+------------------+----------------------+-----------+--------------------+--------------------+----------+
|Gender|Age|Annual Income (k$)|Spending Score (1-100)|Gender_code| features| scaledFeatures|prediction|
+------+---+------------------+----------------------+-----------+--------------------+--------------------+----------+
| Male| 19| 15| 39| 1.0|[15.0,39.0,19.0,1...|[-1.7346462470822...| 4|
| Male| 21| 15| 81| 1.0|[15.0,81.0,21.0,1...|[-1.7346462470822...| 1|
|Female| 20| 16| 6| 0.0|[16.0,6.0,20.0,0....|[-1.6965723610620...| 4|
|Female| 23| 16| 77| 0.0|[16.0,77.0,23.0,0...|[-1.6965723610620...| 1|
|Female| 31| 17| 40| 0.0|[17.0,40.0,31.0,0...|[-1.6584984750417...| 4|
|Female| 22| 17| 76| 0.0|[17.0,76.0,22.0,0...|[-1.6584984750417...| 1|
|Female| 35| 18| 6| 0.0|[18.0,6.0,35.0,0....|[-1.6204245890215...| 4|
|Female| 23| 18| 94| 0.0|[18.0,94.0,23.0,0...|[-1.6204245890215...| 1|
| Male| 64| 19| 3| 1.0|[19.0,3.0,64.0,1....|[-1.5823507030012...| 4|
|Female| 30| 19| 72| 0.0|[19.0,72.0,30.0,0...|[-1.5823507030012...| 1|
| Male| 67| 19| 14| 1.0|[19.0,14.0,67.0,1...|[-1.5823507030012...| 4|
|Female| 35| 19| 99| 0.0|[19.0,99.0,35.0,0...|[-1.5823507030012...| 1|
|Female| 58| 20| 15| 0.0|[20.0,15.0,58.0,0...|[-1.5442768169810...| 4|
|Female| 24| 20| 77| 0.0|[20.0,77.0,24.0,0...|[-1.5442768169810...| 1|
| Male| 37| 20| 13| 1.0|[20.0,13.0,37.0,1...|[-1.5442768169810...| 4|
| Male| 22| 20| 79| 1.0|[20.0,79.0,22.0,1...|[-1.5442768169810...| 1|
|Female| 35| 21| 35| 0.0|[21.0,35.0,35.0,0...|[-1.5062029309608...| 4|
| Male| 20| 21| 66| 1.0|[21.0,66.0,20.0,1...|[-1.5062029309608...| 1|
| Male| 52| 23| 29| 1.0|[23.0,29.0,52.0,1...|[-1.4300551589203...| 4|
|Female| 35| 23| 98| 0.0|[23.0,98.0,35.0,0...|[-1.4300551589203...| 1|
+------+---+------------------+----------------------+-----------+--------------------+--------------------+----------+
only showing top 20 rows
Check Predictions
pred.groupBy('prediction').count().show()
+----------+-----+
|prediction|count|
+----------+-----+
| 1| 25|
| 3| 39|
| 4| 23|
| 2| 36|
| 0| 77|
+----------+-----+
Evaluate best values for k
import numpy as np
ks = np.arange(2, 12)
for k in ks:
kmeans = KMeans().setK(k).setSeed(1)
model = kmeans.fit(scaledData)
predictions = model.transform(scaledData)
evaluator = ClusteringEvaluator()
silhouette = evaluator.evaluate(predictions)
print("Silhouette with squared euclidean distance = " + str(silhouette) + " with %d" % (k))
Silhouette with squared euclidean distance = 0.43394267251692986 with 2
Silhouette with squared euclidean distance = 0.45083945717077895 with 3
Silhouette with squared euclidean distance = 0.5729649517903038 with 4
Silhouette with squared euclidean distance = 0.6274564395632695 with 5
Silhouette with squared euclidean distance = 0.5974977580334055 with 6
Silhouette with squared euclidean distance = 0.6238278103607825 with 7
Silhouette with squared euclidean distance = 0.6053488985934731 with 8
Silhouette with squared euclidean distance = 0.5979227655105717 with 9
Silhouette with squared euclidean distance = 0.5470079039439587 with 10
Silhouette with squared euclidean distance = 0.5449277947111678 with 11
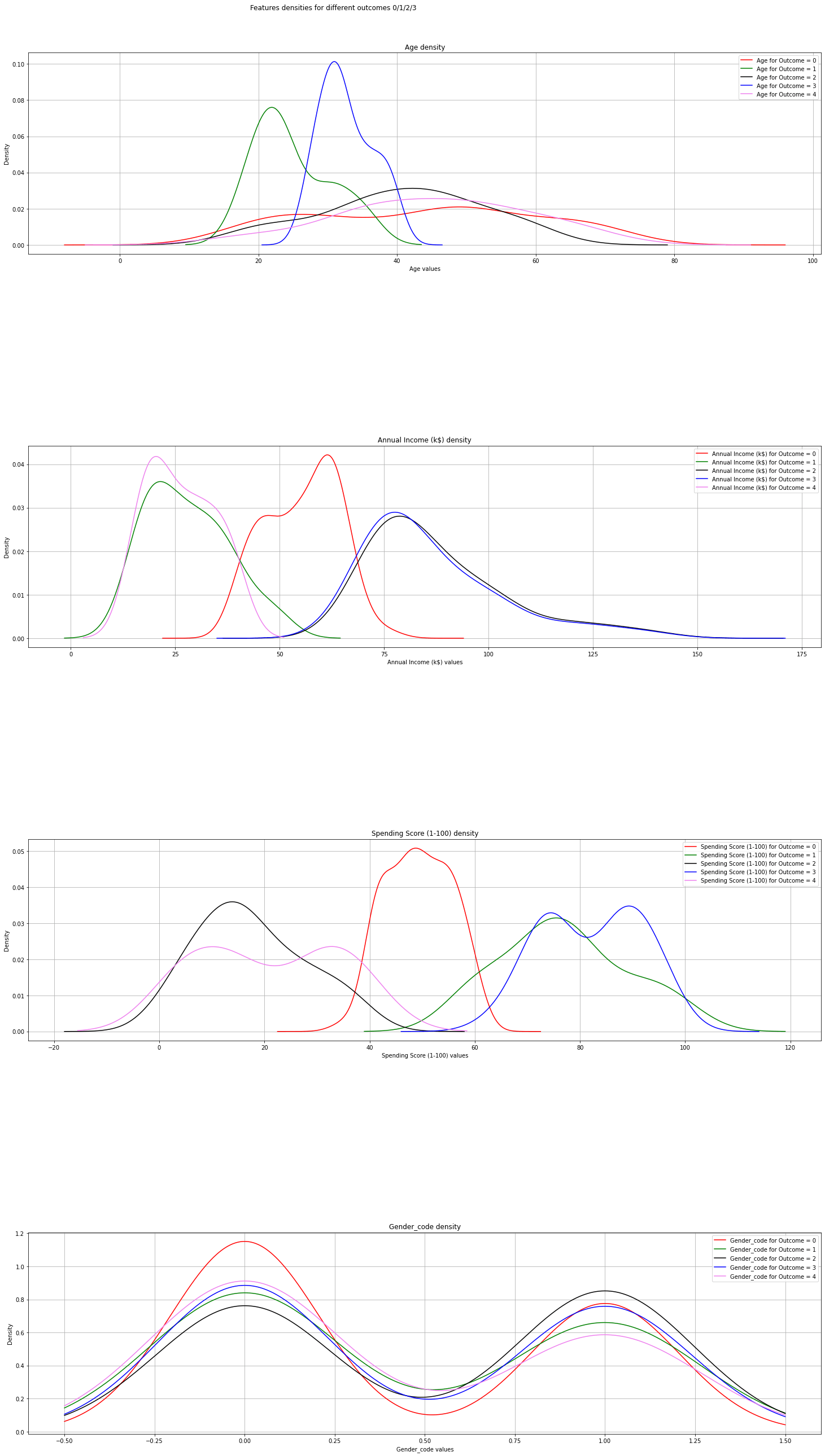
Feature density
import pandas as pd
from pylab import rcParams
import matplotlib.pyplot as plt
def plot_densities(data):
'''
Plot features densities depending on the outcome values
'''
# change fig size to fit all subplots beautifully
rcParams['figure.figsize'] = 30, 40
# separate data based on outcome values
outcome_0 = data[data['prediction'] == 0]
outcome_1 = data[data['prediction'] == 1]
outcome_2 = data[data['prediction'] == 2]
outcome_3 = data[data['prediction'] == 3]
outcome_4 = data[data['prediction'] == 4]
# init figure
fig, axs = plt.subplots(4, 1)
fig.suptitle('Features densities for different outcomes 0/1/2/3')
plt.subplots_adjust(left = 0.25, right = 0.9, bottom = 0.1, top = 0.95,
wspace = 0.2, hspace = 0.95)
# plot densities for outcomes
for column_name in names[:-1]:
ax = axs[names.index(column_name)]
#plt.subplot(4, 2, names.index(column_name) + 1)
outcome_0[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="red", legend=True,
label=column_name + ' for Outcome = 0')
outcome_1[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="green", legend=True,
label=column_name + ' for Outcome = 1')
outcome_2[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="black", legend=True,
label=column_name + ' for Outcome = 2')
outcome_3[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="blue", legend=True,
label=column_name + ' for Outcome = 3')
outcome_4[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="violet", legend=True,
label=column_name + ' for Outcome = 4')
ax.set_xlabel(column_name + ' values')
ax.set_title(column_name + ' density')
ax.grid('on')
plt.show()
fig.savefig('densities.png')
# load your data
data = pred.toPandas()
cols =['Gender','features','scaledFeatures']
data = data.drop(cols, axis=1)
names = list(data.columns)
print(names)
# plot correlation & densities
plot_densities(data)
PCA
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
pca = PCA(2)
#Transform the data
pred = data['prediction']
df = data.drop('prediction', axis = 1)
df
Age Annual Income (k$) Spending Score (1-100) Gender_code
0 19 15 39 1.0
1 21 15 81 1.0
2 20 16 6 0.0
3 23 16 77 0.0
4 31 17 40 0.0
... ... ... ... ...
195 35 120 79 0.0
196 45 126 28 0.0
197 32 126 74 1.0
198 32 137 18 1.0
199 30 137 83 1.0
Check shape
df = pca.fit_transform(df)
df.shape
(200, 2)
#Import required module
from sklearn.cluster import KMeans
#Initialize the class object
kmeans = KMeans(n_clusters= 5)
#predict the labels of clusters.
label = kmeans.fit_predict(df)
print(label)
[3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3
0 3 0 3 0 3 1 3 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 1 2 4 2 4 2 1 2 4 2 4 2 4 2 4 2 1 2 4 2 4 2
4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4
2 4 2 4 2 4 2 4 2 4 2 4 2 4 2]
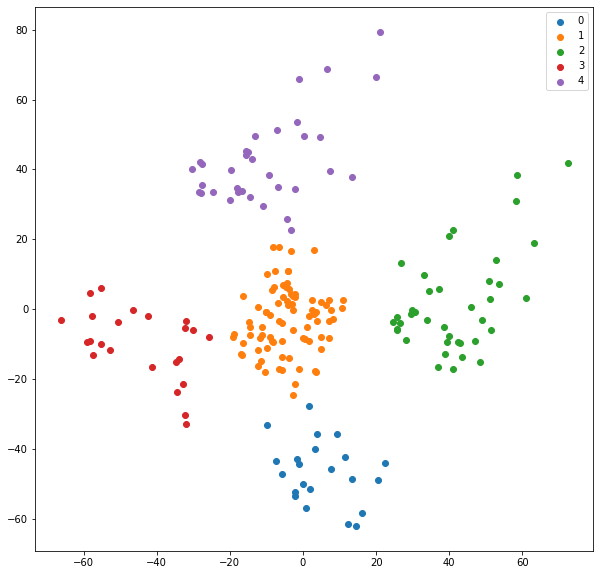
Plot our clusters
#Getting unique labels
u_labels = np.unique(label)
#plotting the results:
rcParams['figure.figsize'] = 10, 10
for i in u_labels:
plt.scatter(df[label == i , 0] , df[label == i , 1] , label = i)
plt.legend()
plt.show()
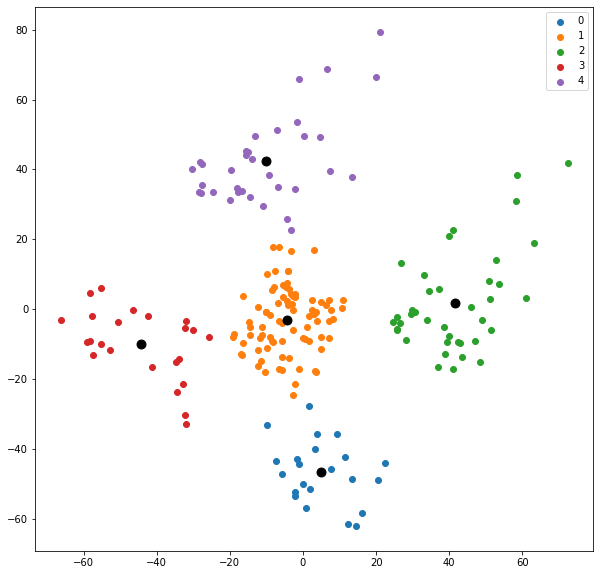
Centroids
#Getting the Centroids
centroids = kmeans.cluster_centers_
u_labels = np.unique(label)
#plotting the results:
for i in u_labels:
plt.scatter(df[label == i , 0] , df[label == i , 1] , label = i)
plt.scatter(centroids[:,0] , centroids[:,1] , s = 80, color = 'k')
plt.legend()
plt.show()